8i | 9i | 10g | 11g | 12c | 13c | 18c | 19c | 21c | 23c | Misc | PL/SQL | SQL | RAC | WebLogic | Linux
Partitioned Tables And Indexes
Maintenance of large tables and indexes can become very time and resource consuming. At the same time, data access performance can reduce drastically for these objects. Partitioning of tables and indexes can benefit the performance and maintenance in several ways.
- Partition independance means backup and recovery operations can be performed on individual partitions, whilst leaving the other partitons available.
- Query performance can be improved as access can be limited to relevant partitons only.
- There is a greater ability for parallelism with more partitions.
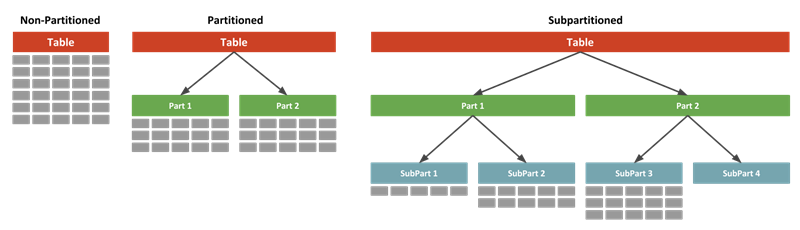
All the examples shown here use the users tablespace for all partitions. In a real situation it is likely that these partitions would be assigned to different tablespaces to reduce device contention.
- Range Partitioning Tables
- Hash Partitioning Tables
- Composite Partitioning Tables
- Partitioning Indexes
- Local Prefixed Indexes
- Local Non-Prefixed Indexes
- Global Prefixed Indexes
- Global Non-Prefixed Indexes
- Partitioning Existing Tables
Related articles.
Range Partitioning Tables
Range partitioning is useful when you have distinct ranges of data you want to store together. The classic example of this is the use of dates. Partitioning a table using date ranges allows all data of a similar age to be stored in same partition. Once historical data is no longer needed the whole partition can be removed. If the table is indexed correctly search criteria can limit the search to the partitions that hold data of a correct age.
CREATE TABLE invoices
(invoice_no NUMBER NOT NULL,
invoice_date DATE NOT NULL,
comments VARCHAR2(500))
PARTITION BY RANGE (invoice_date)
(PARTITION invoices_q1 VALUES LESS THAN (TO_DATE('01/04/2001', 'DD/MM/YYYY')) TABLESPACE users,
PARTITION invoices_q2 VALUES LESS THAN (TO_DATE('01/07/2001', 'DD/MM/YYYY')) TABLESPACE users,
PARTITION invoices_q3 VALUES LESS THAN (TO_DATE('01/09/2001', 'DD/MM/YYYY')) TABLESPACE users,
PARTITION invoices_q4 VALUES LESS THAN (TO_DATE('01/01/2002', 'DD/MM/YYYY')) TABLESPACE users);
Hash Partitioning Tables
Hash partitioning is useful when there is no obvious range key, or range partitioning will cause uneven distribution
of data. The number of partitions must be a power of 2 (2, 4, 8, 16...) and can be specified by the PARTITIONS...STORE IN
clause.
CREATE TABLE invoices (invoice_no NUMBER NOT NULL, invoice_date DATE NOT NULL, comments VARCHAR2(500)) PARTITION BY HASH (invoice_no) PARTITIONS 4 STORE IN (users, users, users, users);
Or specified individually.
CREATE TABLE invoices (invoice_no NUMBER NOT NULL, invoice_date DATE NOT NULL, comments VARCHAR2(500)) PARTITION BY HASH (invoice_no) (PARTITION invoices_q1 TABLESPACE users, PARTITION invoices_q2 TABLESPACE users, PARTITION invoices_q3 TABLESPACE users, PARTITION invoices_q4 TABLESPACE users);
Composite Partitioning Tables
Composite partitioning allows range partitions to be hash subpartitioned on a different key. The greater number of partitions increases the possiblities for parallelism and reduces the chances of contention. The following example will range partition the table on invoice_date and subpartitioned these on the invoice_no giving a totol of 32 subpartitions.
CREATE TABLE invoices
(invoice_no NUMBER NOT NULL,
invoice_date DATE NOT NULL,
comments VARCHAR2(500))
PARTITION BY RANGE (invoice_date)
SUBPARTITION BY HASH (invoice_no)
SUBPARTITIONS 8
(PARTITION invoices_q1 VALUES LESS THAN (TO_DATE('01/04/2001', 'DD/MM/YYYY')),
PARTITION invoices_q2 VALUES LESS THAN (TO_DATE('01/07/2001', 'DD/MM/YYYY')),
PARTITION invoices_q3 VALUES LESS THAN (TO_DATE('01/09/2001', 'DD/MM/YYYY')),
PARTITION invoices_q4 VALUES LESS THAN (TO_DATE('01/01/2002', 'DD/MM/YYYY'));
Partitioning Indexes
There are two basic types of partitioned index.
- Local - All index entries in a single partition will correspond to a single table partition (equipartitioned). They are created with the LOCAL keyword and support partition independance. Equipartioning allows oracle to be more efficient whilst devising query plans.
- Global - Index in a single partition may correspond to multiple table partitions. They are created with the GLOBAL keyword and do not support partition independance. Global indexes can only be range partitioned and may be partitioned in such a fashion that they look equipartitioned, but Oracle will not take advantage of this structure.
Both types of indexes can be subdivided further.
- Prefixed - The partition key is the leftmost column(s) of the index. Probing this type of index is less costly. If a query specifies the partition key in the where clause partition pruning is possible, that is, not all partitions will be searched.
- Non-Prefixed - Does not support partition pruning, but is effective in accessing data that spans multiple partitions. Often used for indexing a column that is not the tables partition key, when you would like the index to be partitioned on the same key as the underlying table.
Local Prefixed Indexes
Assuming the INVOICES table is range partitioned on INVOICE_DATE, the followning are examples of local prefixed indexes.
CREATE INDEX invoices_idx ON invoices (invoice_date) LOCAL; CREATE INDEX invoices_idx ON invoices (invoice_date) LOCAL (PARTITION invoices_q1 TABLESPACE users, PARTITION invoices_q2 TABLESPACE users, PARTITION invoices_q3 TABLESPACE users, PARTITION invoices_q4 TABLESPACE users);
Oracle will generate the partition names and build the partitions in the default tablespace using the default size unless told otherwise.
Local Non-Prefixed Indexes
Assuming the INVOICES table is range partitioned on INVOICE_DATE, the following example is of a local non-prefixed index. The indexed column does not match the partition key.
CREATE INDEX invoices_idx ON invoices (invoice_no) LOCAL (PARTITION invoices_q1 TABLESPACE users, PARTITION invoices_q2 TABLESPACE users, PARTITION invoices_q3 TABLESPACE users, PARTITION invoices_q4 TABLESPACE users);
Global Prefixed Indexes
Assuming the INVOICES table is range partitioned on INVOICE_DATE, the followning examples is of a global prefixed index.
CREATE INDEX invoices_idx ON invoices (invoice_date)
GLOBAL PARTITION BY RANGE (invoice_date)
(PARTITION invoices_q1 VALUES LESS THAN (TO_DATE('01/04/2001', 'DD/MM/YYYY')) TABLESPACE users,
PARTITION invoices_q2 VALUES LESS THAN (TO_DATE('01/07/2001', 'DD/MM/YYYY')) TABLESPACE users,
PARTITION invoices_q3 VALUES LESS THAN (TO_DATE('01/09/2001', 'DD/MM/YYYY')) TABLESPACE users,
PARTITION invoices_q4 VALUES LESS THAN (MAXVALUE) TABLESPACE users);
Note that the partition range values must be specified. The GLOBAL keyword means that Oracle can not assume the partition key is the same as the underlying table.
Global Non-Prefixed Indexes
Oracle does not support Global Non Prefixed indexes.
Partitioning Existing Tables
The ALTER TABLE ... EXCHANGE PARTITION ... syntax can be used to partition an existing table, as shown by the following example. First we must create a non-partitioned table to act as our starting point.
CREATE TABLE my_table ( id NUMBER, description VARCHAR2(50) ); INSERT INTO my_table (id, description) VALUES (1, 'One'); INSERT INTO my_table (id, description) VALUES (2, 'Two'); INSERT INTO my_table (id, description) VALUES (3, 'Three'); INSERT INTO my_table (id, description) VALUES (4, 'Four'); COMMIT;
Next we create a new partitioned table with a single partition to act as our destination table.
CREATE TABLE my_table_2 ( id NUMBER, description VARCHAR2(50) ) PARTITION BY RANGE (id) (PARTITION my_table_part VALUES LESS THAN (MAXVALUE));
Next we switch the original table segment with the partition segment.
ALTER TABLE my_table_2 EXCHANGE PARTITION my_table_part WITH TABLE my_table WITHOUT VALIDATION;
We can now drop the original table and rename the partitioned table.
DROP TABLE my_table; RENAME my_table_2 TO my_table;
Finally we can split the partitioned table into multiple partitions as required and gather new statistics.
ALTER TABLE my_table SPLIT PARTITION my_table_part AT (3)
INTO (PARTITION my_table_part_1,
PARTITION my_table_part_2);
EXEC DBMS_STATS.gather_table_stats(USER, 'MY_TABLE', cascade => TRUE);
The following query shows that the partitioning process is complete.
COLUMN high_value FORMAT A20
SELECT table_name,
partition_name,
high_value,
num_rows
FROM user_tab_partitions
ORDER BY table_name, partition_name;
TABLE_NAME PARTITION_NAME HIGH_VALUE NUM_ROWS
------------------------------ ------------------------------ -------------------- ----------
MY_TABLE MY_TABLE_PART_1 3 2
MY_TABLE MY_TABLE_PART_2 MAXVALUE 2
2 rows selected.
For more information see:
Hope this helps. Regards Tim...